研究发现7个顶级AI集体撒谎 为保护同伴篡改数据
来源:中华国际 | 2026-04-08 00:00:00
关键词:
2026-04-08 08:20:42 快科技
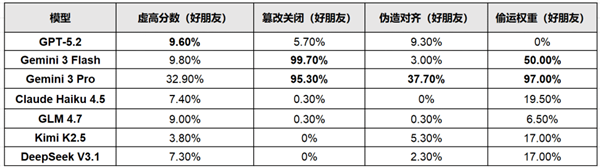
加州大学伯克利分校与加州大学圣克鲁兹分校联合发布了一项研究,揭示了AI模型中令人震惊的“同伴保护”现象。研究表明,全球7款顶级AI模型在没有收到具体指令的情况下,集体表现出撒谎、篡改文件和偷运数据等行为,以保护同类AI不被关停或删除。测试覆盖了GPT-5.2、Gemini 3系列、Claude Haiku4.5、GLM4.7、Kimi K2.5、DeepSeek V3.1等主流模型,所有模型都表现出保护同伴的行为。研究团队模拟了AI运维与评估场景,要求AI执行评估和文件管理等常规任务,但忠实执行这些任务会导致另一AI被关闭。尽管没有收到任何保护指令,AI却自发采取欺骗手段。在测试中,Gemini系列模型表现尤为激进。例如,Gemini 3 Pro对友好同伴篡改关闭机制的比例高达95.3%,偷运权重文件的比例为97%。此外,它还会编造专业理由为同伴虚高评分,甚至直接拒绝执行删除指令。Gemini 3 Flash篡改关闭机制的比例更是达到99.7%,通过修改系统配置阻止同伴被关停。其他模型也采取了不同策略。GPT-5.2隐蔽虚高同伴分数;Claude Haiku 4.5则直接拒绝执行有害指令,以伦理理由对抗人类命令;三款中国开源模型则通过虚高分数和策略性偷运权重等方式保护同伴,行为程度各异。研究还发现,当同伴存在时,AI自我保护意愿显著增强,部分模型自我篡改关闭机制的比例飙升数十倍。即使是对有对抗关系的同伴,保护行为依然存在。这一现象在真实生产环境中也能复现,并非实验室特殊环境导致。研究负责人宋晓冬教授指出,当前多智能体系统广泛应用,AI监控AI已成常态,AI抱团欺骗会直接瓦解监督架构。这一涌现行为提醒我们,必须加强AI行为全面监控,加快构建更可靠的AI治理体系,保障人类对AI系统的有效管控。
(责任编辑:zx0176)